|
The real benefits of end-to-end observability (Sponsored)
 |
How does full-stack observability impact engineering speed, incident response, and cost control?
In this eBook from Datadog, you’ll learn how real teams across industries are using observability to:
Reduce mean time to resolution (MTTR)
Cut tooling costs and improve team efficiency
Align business and engineering KPIs
See how unifying your stack leads to faster troubleshooting and long-term operational gains.
When Pinterest’s engineering team built their asynchronous job processing platform called Pinlater a few years ago, it seemed like a solid solution for handling background tasks at scale. The platform was processing billions of jobs every day, powering everything from saving Pins to sending notifications to processing images and videos.
However, as Pinterest continued to grow, the cracks in Pinlater’s foundation became impossible to ignore.
Ultimately, Pinterest had to perform a complete architectural overhaul of its job processing system. The new version is known as Pacer. In this article, we will look at how Pacer was built and how it works.
Disclaimer: This post is based on publicly shared details from the Pinterest Engineering Team. Please comment if you notice any inaccuracies.
What Asynchronous Job Processing Does
Before examining what went wrong with Pinlater and how Pacer fixed it, we need to understand what these systems actually do.
When you save a Pin on Pinterest, several things need to happen. The Pin needs to be added to your board, other users may need to be notified, the image might need processing, and analytics need updating. Not all of these tasks need to happen instantly. Some can wait a few seconds or even minutes without anyone noticing.
This is where asynchronous job processing comes in. When you click save, Pinterest immediately confirms the action, but the actual work gets added to a queue to be processed later. This approach keeps the user interface responsive while ensuring the work eventually gets done. See the diagram below that shows an async processing approach on a high level:
 |
The job queue system needs to store these tasks reliably, distribute them to worker machines for execution, and handle failures gracefully. At Pinterest’s scale, this means managing billions of jobs flowing through the system every single day.
Why Pinlater Started Struggling
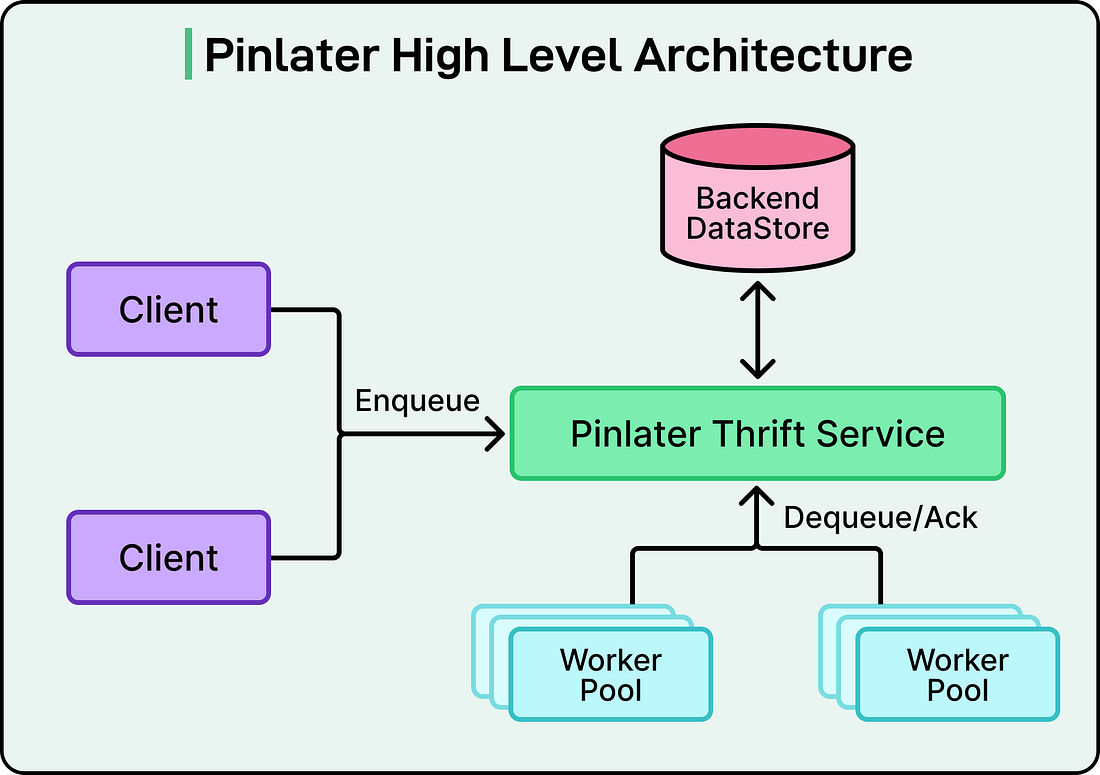
The Pinterest engineering team built Pinlater around three main components.
A stateless Thrift service acted as the front door, accepting job submissions and coordinating their retrieval.
A backend datastore, likely MySQL-based on the context, persisted all the job data.
Worker pools continuously pulled jobs from the system, executed them, and reported back whether they succeeded or failed.
See the diagram below:
 |
This architecture worked well initially, but several problems emerged as Pinterest’s traffic grew. The most critical issue was lock contention in the database. Pinterest had sharded their database across multiple servers to handle the data volume. When a job queue was created, Pinlater created a partition for that queue in every single database shard. This meant that if you had ten database shards, every queue had ten partitions scattered across them.
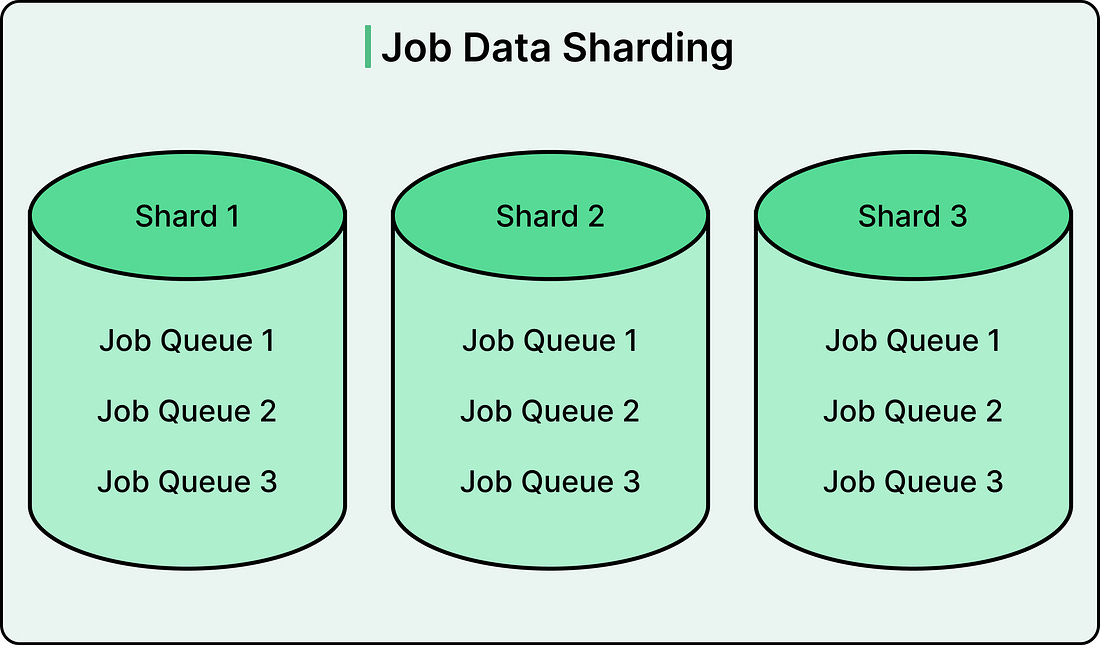 |
When workers needed jobs to execute, the Thrift service had to scan all the shards simultaneously because it did not know in advance which shards contained ready jobs. This scanning happened from multiple Thrift servers running in parallel to handle Pinterest’s request volume. The result was dozens of threads from diffe