|
2026 AI predictions for builders (Sponsored)
 |
The AI landscape is changing fast—and the way you build AI systems in 2026 will look very different.
Join us live on January 28 as we unpack the first take from Redis’ 2026 predictions report: why AI apps won’t succeed without a unified context engine.
You’ll learn:
One architectural standard for AI across teams
Lower operational overhead via shared context infrastructure
Predictable, production-grade performance
Clear observability and governance for agent data access
Faster time to market for new AI features
Read the full 2026 predictions report →
Netflix is no longer just a streaming service. The company has expanded into live events, mobile gaming, and ad-supported subscription plans. This evolution created an unexpected technical challenge.
To understand the challenge, consider a typical member journey. Assume that a user watches Stranger Things on their smartphone, continues on their smart TV, and then launches the Stranger Things mobile game on a tablet. These activities happen at different times on different devices and involve different platform services. Yet they all belong to the same member experience.
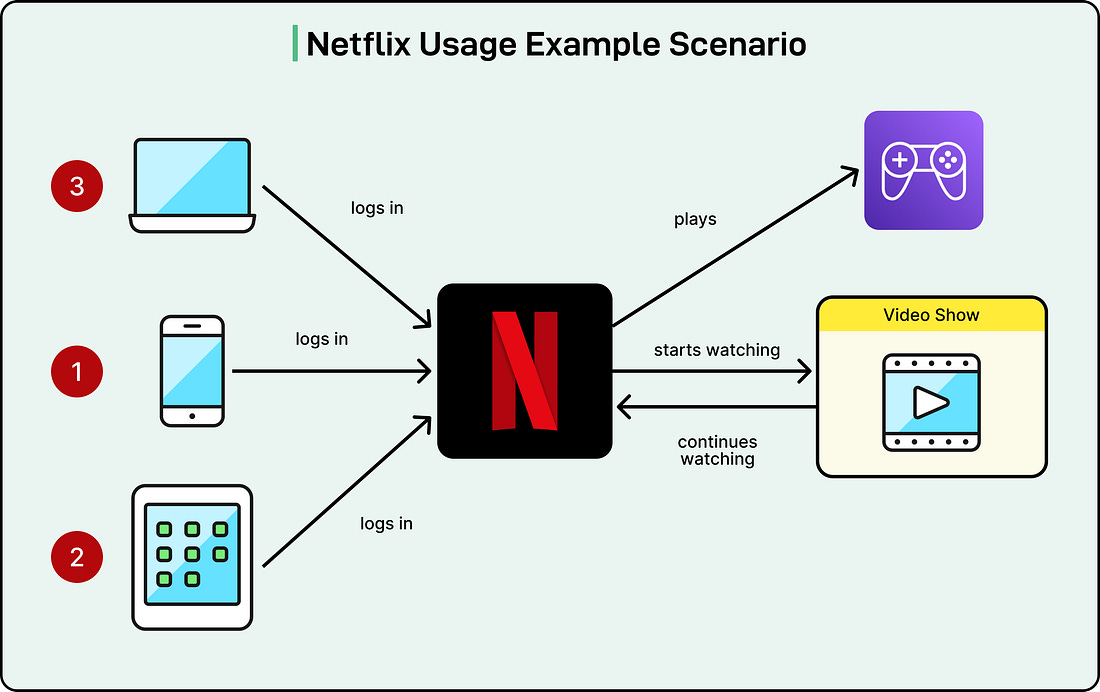 |
Disclaimer: This post is based on publicly shared details from the Netflix Engineering Team. Please comment if you notice any inaccuracies.
Understanding these cross-domain journeys became critical for creating personalized experiences. However, Netflix’s architecture made this difficult.
Netflix uses a microservices architecture with hundreds of services developed by separate teams. Each service can be developed, deployed, and scaled independently, and teams can choose the best data storage technology for their needs. However, when each service manages its own data, information can become siloed. Video streaming data lives in one database, gaming data in another, and authentication data separately. Traditional data warehouses collect this information, but the data lands in different tables and processes at different times.
Manually stitching together information from dozens of siloed databases became overwhelming. Therefore, the Netflix engineering team needed a different approach to process and store interconnected data while enabling fast queries. They chose a graph representation for the same due to the following reasons:
First, graphs enable fast relationship traversals without expensive database joins.
Second, graphs adapt easily when new connections emerge without significant schema changes.
Third, graphs naturally support pattern detection. Identifying hidden relationships and cycles is more efficient using graph traversals than siloed lookups.
This led Netflix to build the Real-Time Distributed Graph, or RDG. In this article, we will look at the architecture of RDG and the challenges Netflix faced while developing it.
Building the Data Pipeline
The RDG consists of three layers: ingestion and processing, storage, and serving. See the diagram below:
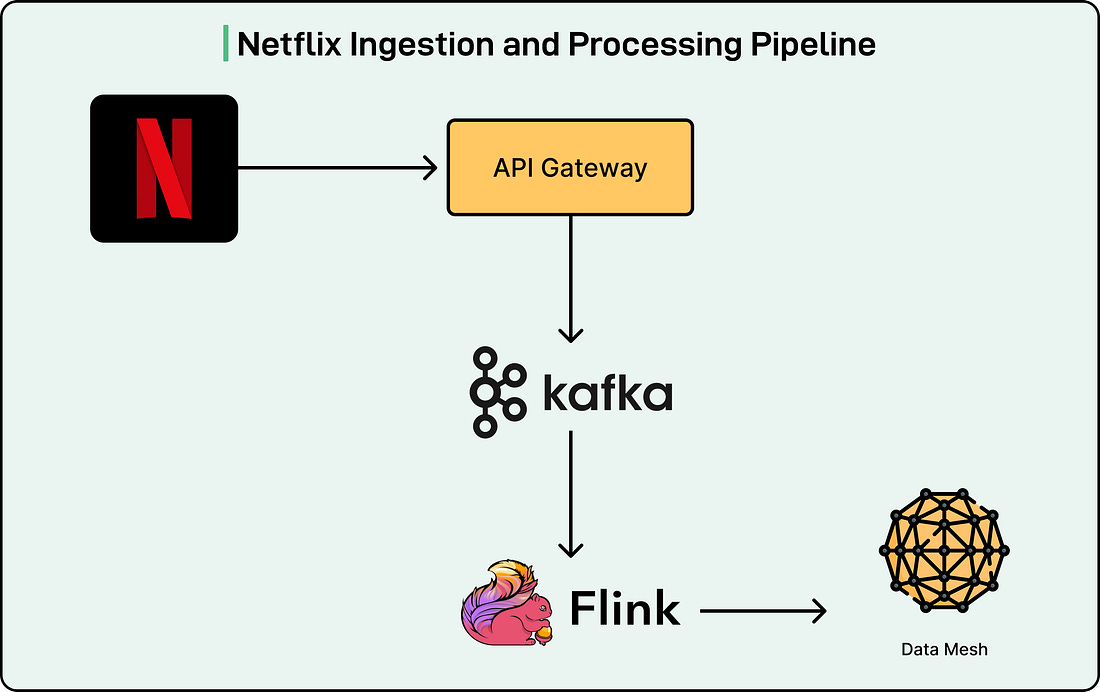 |
When a member performs any action in the Netflix app, such as logging in or starting to watch a show, the API Gateway writes these events as records to Apache Kafka topics.
Apache Kafka serves as the ingestion backbone, providing durable, replayable streams that downstream processors can consume in real time. Netflix chose Kafka because it offers exactly what they needed for building and updating the graph with minimal delay. Traditional batch processing systems and data warehouses could not provide the low latency required to maintain an up-to-date graph supporting real-time applications.
The scale of data flowing through these Kafka topics is significant. For reference, Netflix’s applications consume several different Kafka topics, each generating up to one million messages per second. Records use Apache Avro format for encoding, with schemas persisted in a centralized registry. To balance data availability against storage infrastructure costs, Netflix tailors retention policies for each topic based on throughput and record size. They also persist topic records to Apache Iceberg data warehouse tables, enabling backfills when older data expires from Kafka topics.
Apache Flink jobs ingest event records from the Kafka streams. Netflix chose Flink because of its strong capabilities around near-real-time event processing. There is also robust internal platform support for Flink within Netflix, which allows jobs to integrate with Kafka and various storage backends seamlessly.
A typical Flink job in the RDG pipeline follows a series of processing steps:
First, the job consumes event records from upstream Kafka topics.
Next, it applies filtering and projections to remove noise based on which fields are present or absent in the events.
Then it enriches events with additional metadata stored and accessed via side inputs.